By Jitendra Mohan, CEO and Co-Founder
The Generative AI revolution is reshaping all industries and redefining what’s possible in every aspect of our lives. Behind the scenes, the rapid pace of innovation is creating significant challenges for data center infrastructure, including:
- Exploding demand for AI processing resources that must be interconnected across the data center due to the need for Large Language Models to simultaneously process massive multi-modal datasets (text, images, audio, and video).
- Large number of platform architectures being deployed at a significantly accelerated, annual upgrade cadence due to the diversity and customization of Generative AI applications.
- Maximum uptime and utilization of deployed AI infrastructure due to the incredible financial pressure on Cloud providers to deliver significant ROI for massive capital expenditure.
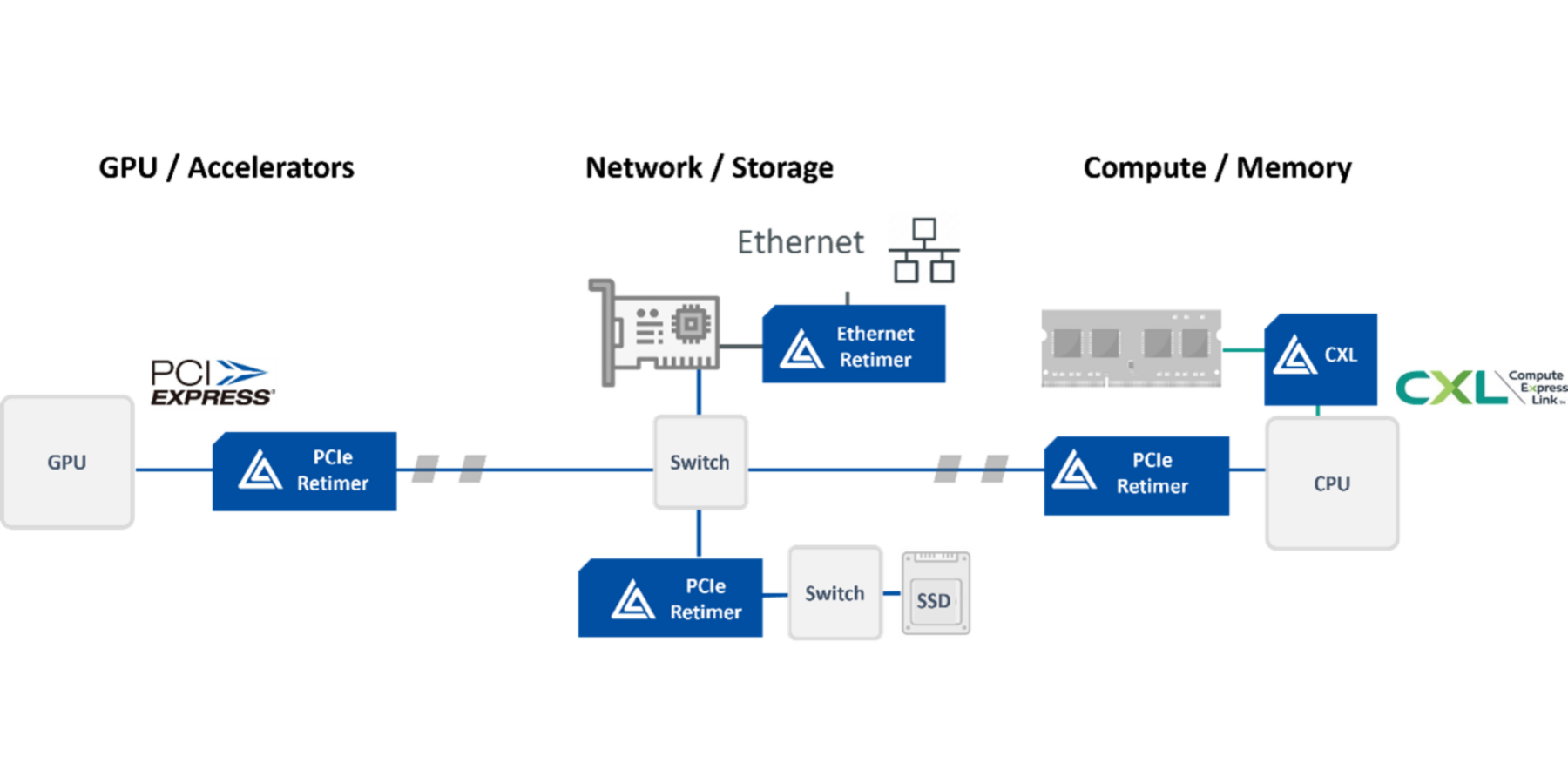
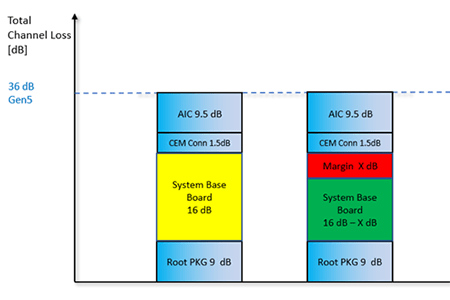
The compute requirements of modern AI models can only be met by interconnecting thousands of GPUs or AI accelerators together with a dedicated network/fabric that is purpose-built for AI workloads. This network, often referred to as the “backend” network, consists of a “scale-up” accelerator clustering fabric and a “scale-out” networking fabric. Scale-up fabric is often an any-to-any mesh interconnect optimized for maximum throughput and the ability to tightly couple the accelerators to rapidly exchange AI model training/inferencing data. Examples of scale-up interconnects include NVLink, Infinity Fabric, PCI Express® (PCIe®), Ethernet, etc. These technologies are used to connect up to hundreds of accelerators. The PCIe interface is natively available on AI accelerators and GPUs, and some of the AI platforms also leverage PCIe or PCIe-based protocols for scale-up fabrics. As the size of AI clusters is increasing from 1-2 racks with tens of GPUs to large pods spanning multiple racks and hundreds of GPUs, interconnect length quickly becomes a limitation. At PCIe 5.0 data rates, Active Electrical Cables (AECs) spanning up to 7 meters are sufficient to interconnect a few racks. However, at higher data rates like PCIe 6.x and PCIe 7.x, optical solutions are needed for GPU clusters spanning multiple racks.

We are excited to continue Astera Labs’ leadership in PCIe connectivity solutions by demonstrating end-to-end PCIe/CXL over optics for GPU clustering, which is lighting the path forward for scaling Generative AI infrastructure!
Addressing Everyday AI-interconnect Challenges
Since 2017, Astera Labs has been laser-focused on unleashing the full potential of AI and Cloud infrastructure through a consistent drumbeat of releasing first-to-market, highly innovative connectivity solutions. The foundation of our Intelligent Connectivity Platform is PCIe®, CXL®, and Ethernet semiconductor-based solutions, along with our COSMOS software suite of system management and optimization tools. This platform delivers a software-defined architecture that is both scalable and customizable.
Facing major challenges in Generative AI infrastructure build-outs, all major hyperscalers and AI platform providers utilize our Intelligent Connectivity Platform which is proven to:
- Deliver reliable connectivity over distance and scale including chip-to-chip, box-to-box, rack-to-rack; and now, we deliver the capability to extend this to row-to-row with PCIe over optics in order to accelerate the deployment of the largest GPU clusters that must scale across the data center.
- Accelerate time-to-deployment of vastly diverse AI platforms through our software-defined architecture and tremendous investment in up-front, interoperability testing at cloud-scale.
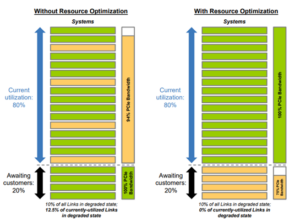
- Enable unprecedented visibility into the ever-increasing number of connectivity links through deep diagnostics, telemetry, and fleet management that facilitate maximum uptime and system utilization of expensive AI infrastructure.

The product families that anchor our Intelligent Connectivity Platform include:
Aries PCIe/CXL Smart DSP Retimers are field-tested and widely deployed by all major hyperscalers and platform providers. Our third generation Aries 6 Retimers double the bandwidth to 64GT/s per lane support and are now sampling. Our Aries PCIe/CXL Smart Cable Modules™ (SCM) deliver an industry-first 7-meter reach over Active Electrical Cables (AECs) for rack-to-rack PCIe connectivity.
Taurus Ethernet Smart Cable Modules (SCM) support Ethernet rates up to 100Gb/s per lane in various form-factors that support robust, thin, and flexible cables for Switch-to-Switch and Switch-to-Server connectivity applications.
Leo CXL Smart Memory Controllers are the industry’s first solution to support CXL memory expansion, pooling, and sharing. They are optimized to meet the growing computational needs of Generative AI workloads at low latency.
We have a rich history of introducing and providing solutions early in the technology cycle to maximize platform utilization. This includes our first-to-market PCIe and CXL solutions and the expansion of our comprehensive Cloud-Scale Interop Lab, which enables confidence in deploying advanced solutions at scale.
New Paradigm for Seamless AI Connectivity
As AI infrastructure build-outs grow beyond single racks and exceed the reach of traditional passive Direct Attach Cables (DACs), new connectivity solutions must be developed. Signal loss at higher speeds also limits the effectiveness of passive solutions, demanding new active cables with improved reach and routing to complement the passive offerings.
Our Aries PCIe/CXL SCM™ delivers 7 meters reach over Active Electrical Cables (AECs), addressing the limitations of DACs. These cost-effective AECs with low latency enable thin cabling to easily scale AI accelerator clusters beyond a rack.

As data rates increase to PCIe 6.x (64GT/s), PCIe 7.x (128GT/s) and beyond, conventional passive and Active Electrical Cables will be limited to single racks. New solutions like PCIe over optics, including Active Optical Cables (AOCs), will play a larger role in rack-to-rack connectivity to maintain and grow these AI clusters.
Unleashing the Reach of Optical Connectivity for PCIe
Fiberoptic links have become the proven backbone of high-speed Ethernet connectivity, offering long reach data connectivity to cover hyperscale data centers with lightweight, thin optical cables. These benefits can be applied to PCIe connectivity by developing new PCIe over optics solutions, including AOCs, that extend PCIe connectivity to clusters of racks with improved cable management compared to copper.

The application of PCIe/CXL over optics is often driven by low-latency requirements relative to Ethernet, such as cache-coherent memory transactions and parallel processing workloads between GPUs. These applications also demand comprehensive management of the link through the use of specialized software to ensure full protocol compliance and reliability.
Astera Labs provides field-proven, software-defined connectivity solutions developed over multiple generations of PCIe specifications to seamlessly integrate PCIe over optics. We have demonstrated this in end-to-end, fully compliant link connections representative of AI infrastructure deployment use cases. Our PCIe over optics demo includes a CPU head-node root complex to a target GPU and a target remote disaggregated memory system. The ability to demonstrate the first, long distance, fully compliant PCIe link over optics between multiple devices paves the way for new products such as high-speed PCIe over optics. Additionally, this solution leverages comprehensive diagnostics, telemetry, and fleet management features from our COSMOS software suite, which helps accelerate time to deployment and facilitates optimized infrastructure utilization.

In summary, Astera Labs continues to innovate and execute on new connectivity solutions that support the accelerated deployment of AI platforms needed to keep up with rapid advancements of next-generation Generative AI applications. Delivering solutions that utilize a software-defined architecture that builds on our common COSMOS software suite enables flexible and reliable connectivity that spans chip-to-chip, box-to-box, rack-to-rack, and now, with the demonstration of PCIe over optics, row-to-row applications across the data center. This is valuable for hyperscalers and AI platform providers as the integration of diagnostics and telemetry for infrastructure management is a significant investment and can be fully leveraged with our latest PCIe over optics technology. We’re excited to be the first to showcase complete end-to-end optics demonstration with a PCIe 5.0 GPU and a CXL 2.0 memory expander connected to a root complex using PCIe based optical modules.
Additional Resources
- Press Release: Astera Labs First to Demonstrate End-to-End PCIe over Optics for GPU Clusters Across the Data Center
- Video: Demo of End-to-End PCIe over Optics
- Blog: The Long and Short of AI: Building Scalable Data Centers in the PCIe 6.x Era