

Agentic AI is changing what it means to build intelligent infrastructure. Unlike traditional AI workloads that run discrete inference jobs, agentic AI systems must reason across multi-step tasks, coordinate across distributed memory pools, and respond to real-time inputs. Meeting these demands requires more than compute alone. It requires a rethinking of how compute, connectivity, and memory work together at the infrastructure level.
At this same moment, server design is undergoing its most significant architectural shift in years. The accelerating transition to PCIe 6 and beyond is not simply a performance upgrade, it is a fundamental change in how signals are transmitted, encoded, and secured across the data center. Likewise, CXL protocol enables a new era of memory for agentic AI systems.
In this environment, configurations that utilize purpose-built components like Arm’s AGI CPU and Astera Labs’ Aries PCIe®/CXL® Smart DSP Retimers and Leo CXL® Smart Memory Controllers can deliver the bandwidth, reach, and memory scalability needed for next-generation AI deployments.
The Infrastructure Demands of Agentic AI
In agentic AI environments, performance is no longer solely bottlenecked by insufficient compute, but by the inability to move data quickly, keep large working sets accessible, and allocate memory resources efficiently across the system.
This creates three practical infrastructure demands. First, agentic systems need access to large memory regions for weights, KV cache, and intermediate activations without paying the penalty of constant data recomputation or movement. Second, they need tighter coordination between processors and memory so that large working sets remain coherent and usable under real-time, multi-agent activity. Third, they need more flexible memory allocation so capacity can be assigned where it is needed most rather than stranded behind fixed device boundaries.
The degree to which each of these demands can be met directly affects infrastructure efficiency, memory utilization, and the cost of scaling agentic AI deployments. To support this paradigm shift toward agentic AI, memory semantic connectivity is critical with CXL over PCIe 6 links.
Arm AGI: The CPU at the Center of the Agentic Data Center
The Arm AGI CPU introduces Arm’s first production CPU engineered for next-generation AI infrastructure, enabling up to 2x the performance per rack compared to x86 counterparts.1 Every SKU has 96 lanes of PCIe 6 and native CXL 3 Type 3 memory expansion support. With up to 136 Neoverse V3 cores delivering 6 GB/s of memory bandwidth per core at sub-100ns latency, and support for up to 6TB of DDR5-8800 RAM, this chip is designed to efficiently orchestrate agentic AI workloads.
Arm AGI aligns directly with the workload pressures above by combining native PCIe 6 and CXL 3 support with the RAS and scalable memory expansion needed for Agentic AI systems. Rather than simply increasing interface speed, the AGI CPU provides the system level bandwidth, reliability, and connectivity foundation required to keep accelerators and memory resources efficiently coordinated as these workloads scale.
PCIe 6 for Agentic AI: Higher Performance Than Gen 5, Smaller Margin for Error
Agentic AI platforms are driving the need for higher bandwidth interconnects to move increasing amounts of data across CPUs, GPUs, memory, and scale-up and out infrastructure. However, as protocols like PCIe 6 increase throughput for agentic workloads, the channel becomes significantly more difficult to manage. At the same time, package loss, PCB material loss, internal cable routing, and endpoint connectors all consume the insertion-loss budget, making reliable connectivity a system-wide challenge.
NRZ to PAM4: Trading Signal Margin for Throughput
PCIe 5 and earlier generations use NRZ (Non-Return-to-Zero) signaling, where each symbol represents a single bit. This produces one large, well-defined eye opening, giving receivers a comfortable signal margin.
PCIe 6 replaces NRZ with PAM4 (Pulse Amplitude Modulation, 4-level), where each symbol encodes 2 bits using four voltage levels instead of two. By encoding 2 bits per symbol, PCIe 6 reaches 64 GT/s per lane while maintaining a 16GHz Nyquist frequency (the same as PCIe 5), which enables 128 GB/s unidirectional bandwidth.
To compensate for PAM4’s reduced signal margin, PCIe 6 implements FLIT-based (Flow Control Unit) packetization along with FEC (Forward Error Correction), enabling data to be sent in fixed size flow control units while detecting and correcting errors in-flight rather than relying on retransmission. This reduces retry overhead and improves effective latency. Even with the benefits of FLIT and FEC, there is still a significant tradeoff in signal integrity in PCIe 6. Instead of one large eye, PAM4 creates three smaller eye openings, each roughly one-third the height of an NRZ eye. The result is significantly reduced noise margin, making the link far more sensitive to signal degradation, jitter, and channel loss.
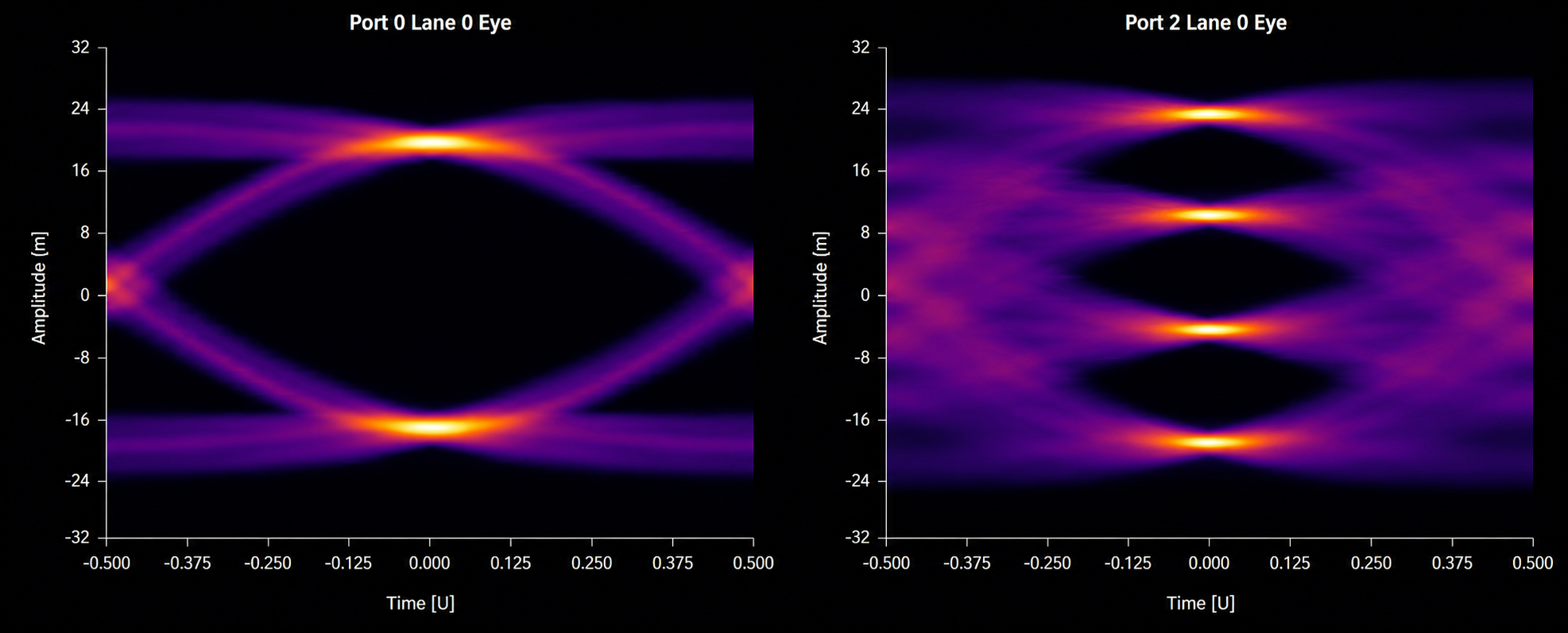
NRZ eye (left) vs PAM-4 eye (right)
The Signal Integrity Challenges with PCIe 6
While offering double the bandwidth of PCIe 5, PCIe 6 tightens the insertion loss budget from 36 dB to 32 dB. This results in shorter usable trace lengths, less margin for connectors and vias, and a channel that runs out of budget quickly in virtually any PCIe topology.
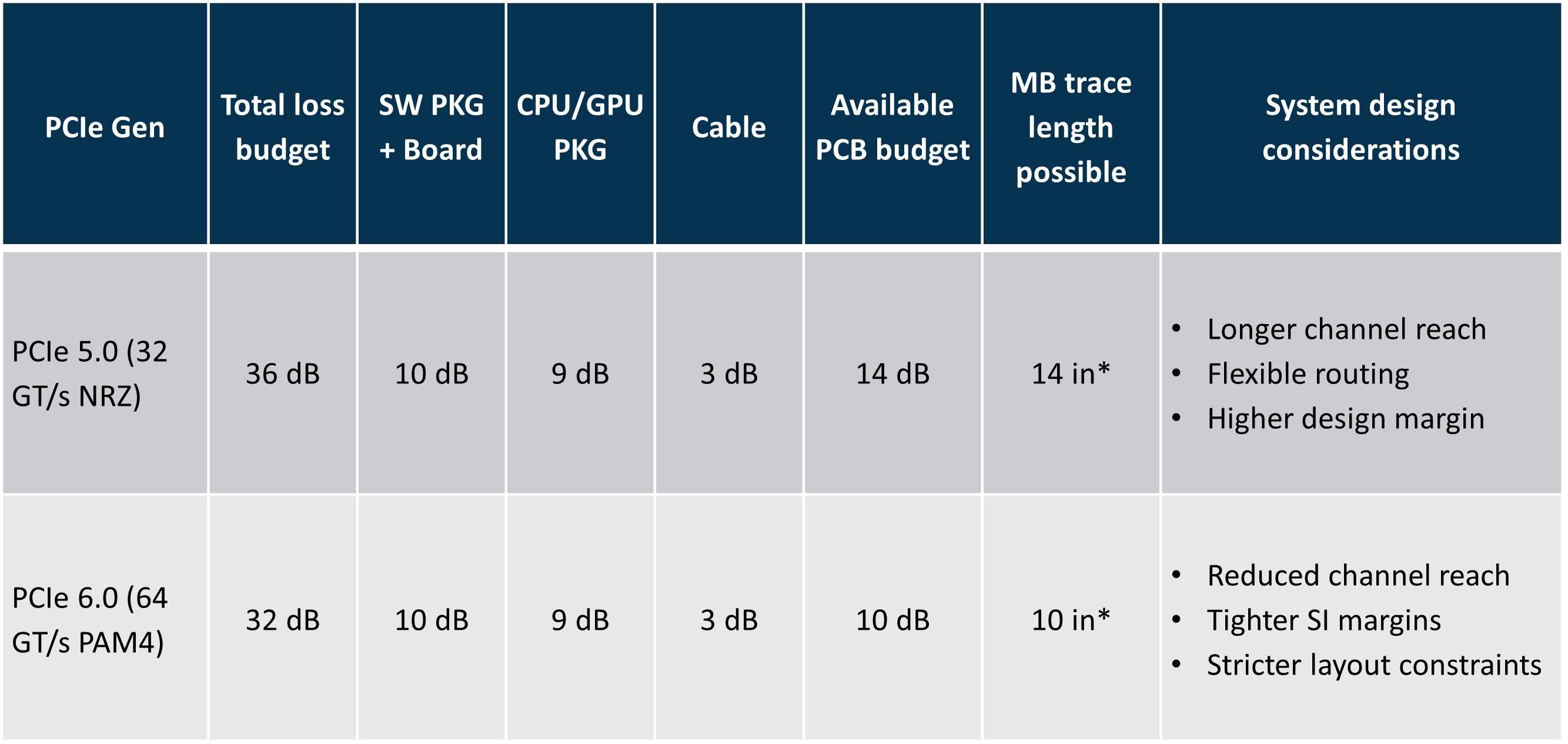
*MB trace length possible is based on theoretical reach on Megtron-7 PCB material with 1dB/inch loss2
The Cost of Higher Throughput
PAM4 doesn’t just reduce margin, it amplifies the impact of every imperfection in the channel. Compared to NRZ, PAM4 is significantly more sensitive to common signal impairments especially as trace lengths increase:
- Crosstalk: Interference from nearby high-speed components and adjacent lanes can couple into the signal path, making placement, spacing, and isolation more critical.
- Jitter: Random and deterministic jitter further compresses an already narrow eye opening.
- Reflections: From vias, stubs, and connectors, causing multi-path interference that becomes harder to tolerate as channel length and reach increase.
- Insertion loss: Cumulative attenuation that reduces signal amplitude and eye height, leaving less overall margin across the link.
The combined effect is a dramatically tighter signal integrity budget, where small imperfections can have outsized impact. Layouts that worked at 32 GT/s with NRZ often fail at 64 GT/s with PAM4, or worse, appear stable while silently retraining or dropping to lower link speeds while under stress.
Why PCIe Gen 6 Systems Require Active Signal Conditioning
A PCIe retimer is a protocol-aware signal conditioner. Unlike passive traces or cables, which simply attenuate and distort signals, a retimer receives a degraded signal, recovers the clock and data, and retransmits a clean, specification-compliant output. In doing so, it effectively resets insertion loss, jitter, and skew, allowing the link to start fresh from that point.
At PCIe 6 speeds, channel loss accumulates quickly even in simple topologies. For example, a typical server path from CPU to NIC, loss across traces and connectors approaches or even surpasses the full 32 dB insertion loss budget.
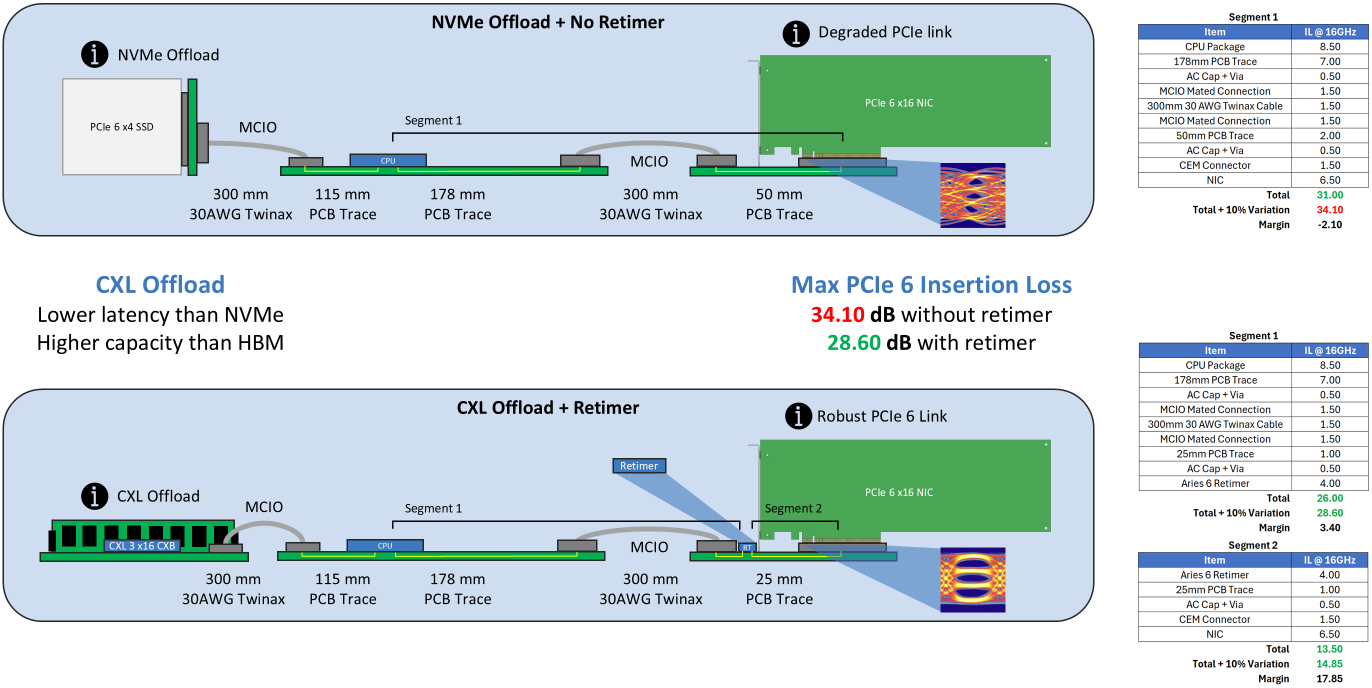
CXL expands memory capacity beyond HBM; with a retimer, the PCIe 6 channel stays within specification.
This leaves minimal margin for variation due to manufacturing, temperature, or aging. As a result, links that appear functional can become unstable, retrain under load, or fail entirely. Placing a retimer at a link boundary creates independent segments, each with its own loss budget, restoring signal quality and margin.
Retimers don’t just recover signal integrity, they restore the architectural headroom that PCIe 6 demands across the broader system. Reinforcing the reliability of PCIe 6 infrastructure is a necessary condition for full utilization of CXL 3 to expand system memory.
Scaling Memory for the Agentic Era With CXL
Running natively over PCIe physical layer, CXL protocol increases link bandwidth versus prior generations, but the bigger opportunity for agentic AI is not bandwidth alone. Agentic workloads are often constrained by memory capacity, locality, and data movement for model weights, KV cache, and intermediate state. In practice, many large AI systems become memory-bound before they become compute-bound, which makes a more flexible memory hierarchy just as important as faster interconnect speeds.
CXL addresses this broader memory bottleneck by extending memory beyond the local host and enabling system-level sharing. Rather than treating memory as a fixed resource attached to a single CPU, CXL makes it possible to expand, pool, and share memory across multiple hosts more efficiently. That shift matters for LLMs and agentic AI because these workloads often need terabytes of addressable memory, and traditional DRAM scaling is limited by the CPU’s physical memory channels. HBM improves bandwidth, but at the cost of capacity. CXL 3 helps bridge that gap by supporting larger and more scalable memory architectures.
An Ecosystem Aligned on Agentic AI-Ready Infrastructure
Not just an incremental upgrade, PCIe 6 defines the connectivity foundation for next-generation AI inference. PAM4 signaling makes active signal conditioning non-negotiable, while CXL enables scalable, shared memory. Arm AGI delivers a power-efficient CPU with native PCIe Gen 6 and CXL support, while Astera Labs complements this with Aries retimers for signal integrity and Leo controllers to expand memory.
Agentic AI is fundamentally memory-bound, demanding infrastructure that scales capacity independently from compute while sustaining reliable, high-speed data movement. Curious how CXL-expanded memory performs under real agentic workloads? Stay tuned, benchmarks are on the way.
References:
- Arm AGI CPU Overview: Arm Holdings. Arm AGI CPU. Arm, 2026.
- PCI Express Specification: PCI-SIG. PCI Express Base Specification Revision 6.3. PCI-SIG, 2025.